

Have you ever stared at a complicated spreadsheet, or a collection of images, or a stream of seemingly random posts, and asked, “But what does it mean?”
Semantics is the study of words, symbols, and signs, based on their connection to one another; their context. For all its complexity, data is simply a collection of symbols.
Understanding data, and helping people make sense of it, is what we are all about. In fact, using semantics to augment human intelligence is who we are: Semantic AI.
The world is made of data sources. Every form, every transaction, every post/tweet/message, is stored in a data source somewhere. All those data sources vary. It is only by seeing all the data, from every disparate data source, connected, in a common format, in context, that we can truly “know” an entity.
Entity-based computing is the insistence on treating every person, place, thing, event or idea as a discrete entity, assigning them one or more “types,” and merging all known data about the entity into a unique representation of that entity. By using a unique identifier for each entity and connecting all known data to it, via named, bi-directional relationships, it is possible to get a holistic view of that unique entity. It also becomes possible to query the data based on individual entities, entity types, and their relationships, to explore the many facets of each unique entity and the world in which they live.
It gets particularly interesting when clusters of connected entities that describe something complex, like an investigation, are themselves entities – so that you can see across multiple connected networks of complex information and understand what’s happening at a macro level too.
Developing expertise is a process comprised of a) learning all the key “facts”, b) learning how the key facts are related, and c) increasing your depth of understanding of the relationships and their impacts on the facts.
Within every domain, industry or sector, there are a core set of relationships. These relationships define the important causal, attributable and procedural relationships between all the entities that matter within the domain. As the nature of the domain, and our understanding of it evolves over time, the relationships change and evolve as well. These relationships may be symmetric, or asymmetric, and many different relationships may connect any two entities. Understanding the relationships allow us to describe the domain in a common language that enables consistent representation over time and across data sources.
While relational databases are good at storing, querying and accessing huge volumes of data, they are relational in name only: They are almost completely ignorant of the relationships connecting the data they hold.
Indeed, if every data point is an entity, and every entity is represented by a node, and every node is connected via bi-directional, named relation rays, then we have created a graph, or network. Graphs are powerful models for knowledge representation. Our scientific founders were using semantic networks for education in the 1980’s. We discovered that virtually any complex knowledge domain could be represented in a graph, and that representation model was easy for people to navigate and led rapidly to real understanding. And unlike other models with brittle tables and rows, adding new data, or changing the data, was just as simple. It turns out that a graph makes the basis for an extremely flexible data schema, that’s amenable to both human understanding, and computational analysis. Once in graph form, we can apply any manner of network analysis techniques – eigenvector centrality, shortest path, social, etc. In addition, the normalized, connected data makes an ideal platform for applying other advanced analytical techniques, like artificial intelligence, machine learning, and others.
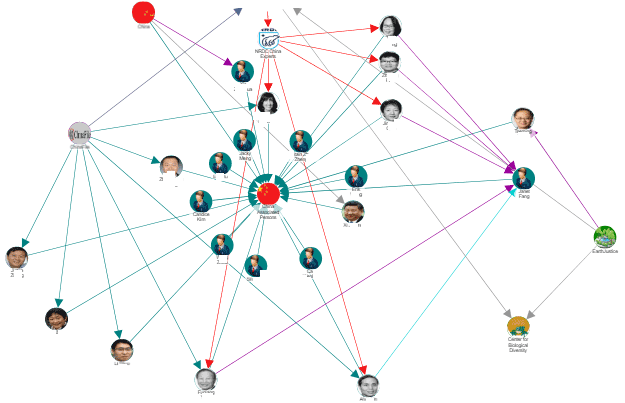
This means the graph is easy to use, easy to change, and easy to learn from. And we can use the power of computers to tell us what is important about the graph – what we need to understand to makes sense of the data it contains.
What we are talking about is a model for computing, based on human cognition, that promotes and supports human understanding, decision-making, and knowledge. We care deeply about how HUMANS make sense of the data streaming around them. How they organize and understand the world -- from their perspective -- as opposed to how a data architect or application developer has attempted to organize it for them (to fit some narrowly defined computational objective). Semantic application development provides a model for PERSONAL data modeling and organization, which is universal, adapts and evolves over time, and can be used to accommodate any computing objective.
Our semantic network intelligence platform has been tested, and battle-hardened in the crucible of the defense and intelligence communities. It has proven capable of making the most complex analysis easy for human users to understand, and act on. We know it can make any user their own “Data Scientist”. And we know it will help you make better, faster, more confident decisions.